Apache Superset from Scratch: Day 6 (Database Class)
December 29, 2021
I ended Day 5 with the knowledge of the Superset shell and a hunch that it might be a better tool for understanding the different code paths for how an example is loaded.
Now I'm going to try running some commands to begin emulating what the app is doing when loading an example. First things first, let's run the utils.get_example_database() function call:
>>> from superset.utils import core as utils
>>> database = utils.get_example_database()
>>> database
examples
Interesting. Superset returns the string value "examples". This is likely just the string representation of the returned "Database" object. We know that the examples database in our Superset installation lives in my home directory, as a SQLite file. So running the next command within the load_world_bank_health_n_pop() function should give us that information:
>>> engine = database.get_sqla_engine()
>>> engine
Engine(sqlite:////Users/srinik/.superset/superset.db)
Success!
The Superset Database Class
Next, I want to better understand the returned database object. The class for Database is defined in superset/superset/models/core.py:
class Database(
Model, AuditMixinNullable, ImportExportMixin
): # pylint: disable=too-many-public-methods
"""An ORM object that stores Database related information"""
__tablename__ = "dbs"
type = "table"
__table_args__ = (UniqueConstraint("database_name"),)
id = Column(Integer, primary_key=True)
verbose_name = Column(String(250), unique=True)
# short unique name, used in permissions
database_name = Column(String(250), unique=True, nullable=False)
...
This is the same file that has the model definition for the CSSTemplate class, as I stumbled into earlier in this series! At the top of core.py is the following text:
A collection of ORM sqlalchemy models for Superset
This file contains the class definitions for the following models:
- Url
- KeyValue
- CssTemplate
- ConfigurationMethod
- Database
- Log
- FavStarClassName
- FavStar
Let's dive deeper into the Database class!
Columns / Fields
The Database class defined in core.py maps to the "dbs" table in the metadata database, as suggested by this line of code:
__tablename__ = "dbs"
What other columns are defined?
id: integer, primary keyverbose_name: string, to specify a more human-friendly name?database_name: string, name of the databasesqlalchemy_uri: string, likely the URI sent to the underlying database driver to connectpassword: salted passwordcache_timeout: integer, corresponding to the cache timeout in seconds at the database levelselect_as_create_table_as: boolean, not sure what this doesexpose_in_sqllab: boolean, should this db be exposed in SQL Lab?configuration_method: string, type of form used to configure?- several
allow_fields around async, file upload, CTAS, CVAS, DML, multi schema metadata fetch, and other user-configurable features - several
extra_fields around encryption, fields, etc. - and more
String Representation
We know from our earlier exploration that running print() on a Superset Database object returns the database name. This aligns with the __repr__() definition for this model!
def __repr__(self) -> str:
return self.name
Name Attribute
If I call the .name attribute on a Database object, the following is evaluated:
def name(self) -> str:
return self.verbose_name if self.verbose_name else self.database_name
Interesting -- now we know how verbose_name is used! It's the preference for showing to humans, and database_name is the backup value displayed.
Data Attribute
What's next? The .data attribute looks interesting:
@property
def data(self) -> Dict[str, Any]:
I want to run this for my Examples SQLite database and see what's returned:
>>> database.data
{'id': 1,
'name': 'examples',
'backend': 'sqlite',
'configuration_method': 'sqlalchemy_form',
'allow_multi_schema_metadata_fetch': False,
'allows_subquery': True,
'allows_cost_estimate': False,
'allows_virtual_table_explore': True,
'explore_database_id': 1,
'parameters': {},
'parameters_schema': {}}
Reserved Words
Neat! I can also retrieve the reserved words for the database:
>>> database.get_reserved_words()
{'right', 'select', 'check', 'having', 'virtual', 'before', 'fail', 'conflict', 'current_timestamp', 'escape', 'full', 'case', 'references', 'drop', 'begin', 'cast', 'view', 'of', 'insert', 'on', 'outer', 'cascade', 'in', 'attach', 'inner', 'vacuum', 'deferred', 'add', 'for', 'temporary', 'union', 'update', 'offset', 'as', 'where', 'transaction', 'explain', 'indexed', 'group', 'limit', 'to', 'pragma', 'unique', 'raise', 'initially', 'distinct', 'column', 'asc', 'notnull', 'null', 'between', 'rollback', 'end', 'when', 'deferrable', 'detach', 'match', 'all', 'temp', 'isnull', 'join', 'trigger', 'query', 'from', 'autoincrement', 'ignore', 'after', 'table', 'order', 'alter', 'reindex', 'is', 'intersect', 'primary', 'then', 'and', 'set', 'like', 'index', 'by', 'default', 'else', 'rename', 'plan', 'except', 'row', 'instead', 'natural', 'analyze', 'foreign', 'database', 'if', 'current_time', 'glob', 'current_date', 'cross', 'key', 'values', 'into', 'constraint', 'exists', 'left', 'delete', 'each', 'or', 'false', 'commit', 'exclusive', 'immediate', 'restrict', 'not', 'create', 'desc', 'true', 'using', 'replace', 'collate'}
Previewing Raw Data
I want to peek at the data in my SQLite database. The DB Browser for SQLite app on Mac is a good option for this. Better yet, once installed, I can use my terminal to pass the app the file location of my sqlite DB!
open -a "DB Browser for SQLite" /Users/srinik/.superset/superset.db
And voila!
Let's preview the dbs table (which corresponds to the Database model).
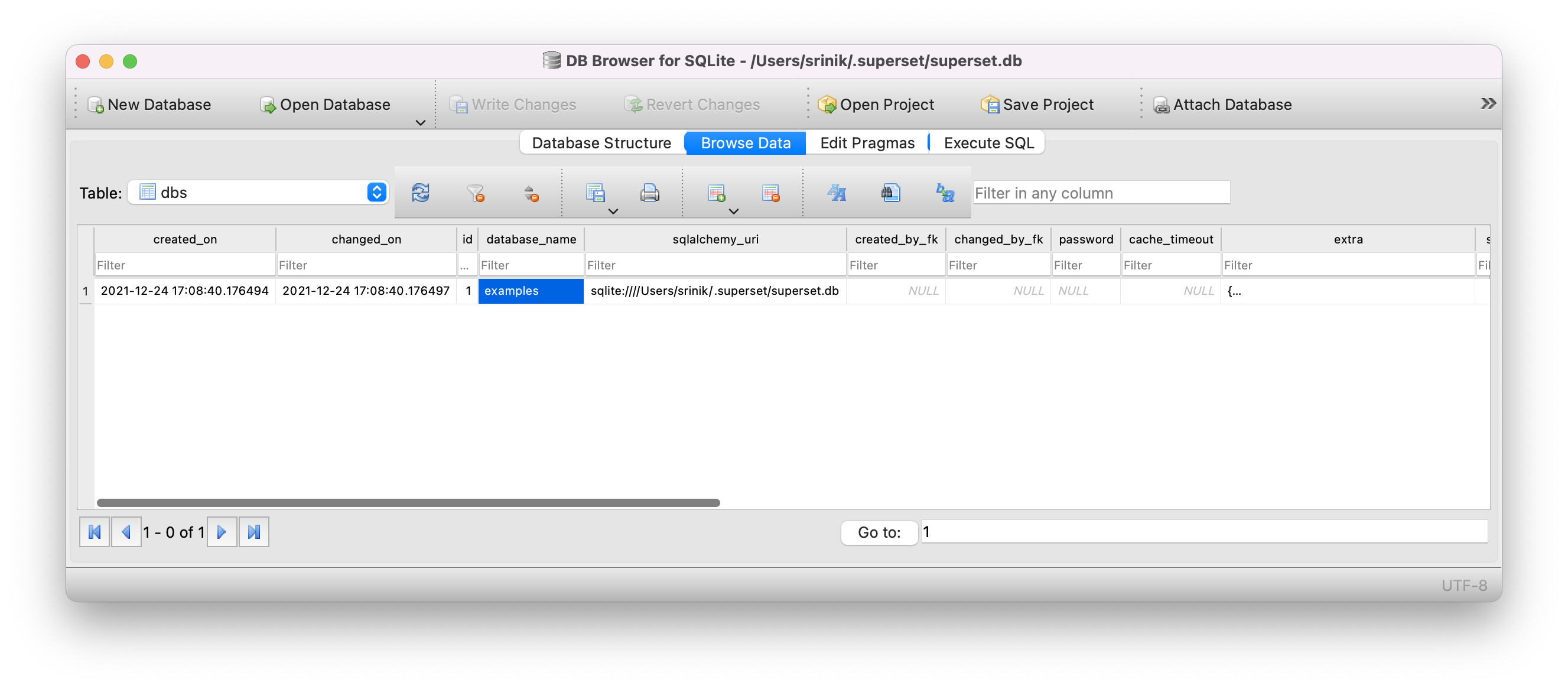
It's nice to see all of the columns reflected here from the Database model.
World Health Dashboard: Examples Database
Let's revisit the load_world_bank_health_n_pop() function that loads the World Health Dashboard.
def load_world_bank_health_n_pop( # pylint: disable=too-many-locals, too-many-statements
only_metadata: bool = False, force: bool = False, sample: bool = False,
) -> None:
"""Loads the world bank health dataset, slices and a dashboard"""
tbl_name = "wb_health_population"
database = utils.get_example_database()
engine = database.get_sqla_engine()
schema = inspect(engine).default_schema_name
table_exists = database.has_table_by_name(tbl_name)
This code does the following:
- Sets the table name to
wb_health_population - Uses utility functions to fetch the Database object corresponding to the
examplesdatabase (or creates it if it isn't there) - Retrieves the SQLAlchemy engine for this specific database flavor (from the
db_engine_specsfolder) so queries can be made to the database. - Retrieves the default schema name if it exists.
- Confirms if the
wb_health_populationtable exists or not.
World Health Dashboard: Pandas Transformation
As someone who's spent years writing pandas code, the next part of of the load_world_bank_health_n_pop() function looks very familiar:
if not only_metadata and (not table_exists or force):
data = get_example_data("countries.json.gz")
pdf = pd.read_json(data)
pdf.columns = [col.replace(".", "_") for col in pdf.columns]
if database.backend == "presto":
pdf.year = pd.to_datetime(pdf.year)
pdf.year = pdf.year.dt.strftime("%Y-%m-%d %H:%M%:%S")
else:
pdf.year = pd.to_datetime(pdf.year)
pdf = pdf.head(100) if sample else pdf
pdf.to_sql(
tbl_name,
engine,
schema=schema,
if_exists="replace",
chunksize=50,
dtype={
# TODO(bkyryliuk): use TIMESTAMP type for presto
"year": DateTime if database.backend != "presto" else String(255),
"country_code": String(3),
"country_name": String(255),
"region": String(255),
},
method="multi",
index=False,
)
Here's my breakdown of the code:
data = get_example_data("countries.json.gz"):get_example_data()is a helper function that fetches the gzipped JSON dataset for this example fromhttps://github.com/apache-superset/examples-data/blob/master/countries.json.gz
pdf = pd.read_json(data):- read in JSON as a pandas dataframe
pdf.columns = [col.replace(".", "_") for col in pdf.columns]:- replace any periods with
_, so the database is happy
- replace any periods with
if database.backend == "presto":if the examples Database object points to a Presto database, do some specific datetime conversion for Presto.pdf.to_sql(): use thepandas.DataFrame.to_sql()method to generate a SQLAlchemy 'query' to insert data into the database.
Phew! That's it for today. Tomorrow, I want to finish understanding how the Superset-specific metadata is loaded.